AI knowledge assistant (RAG)
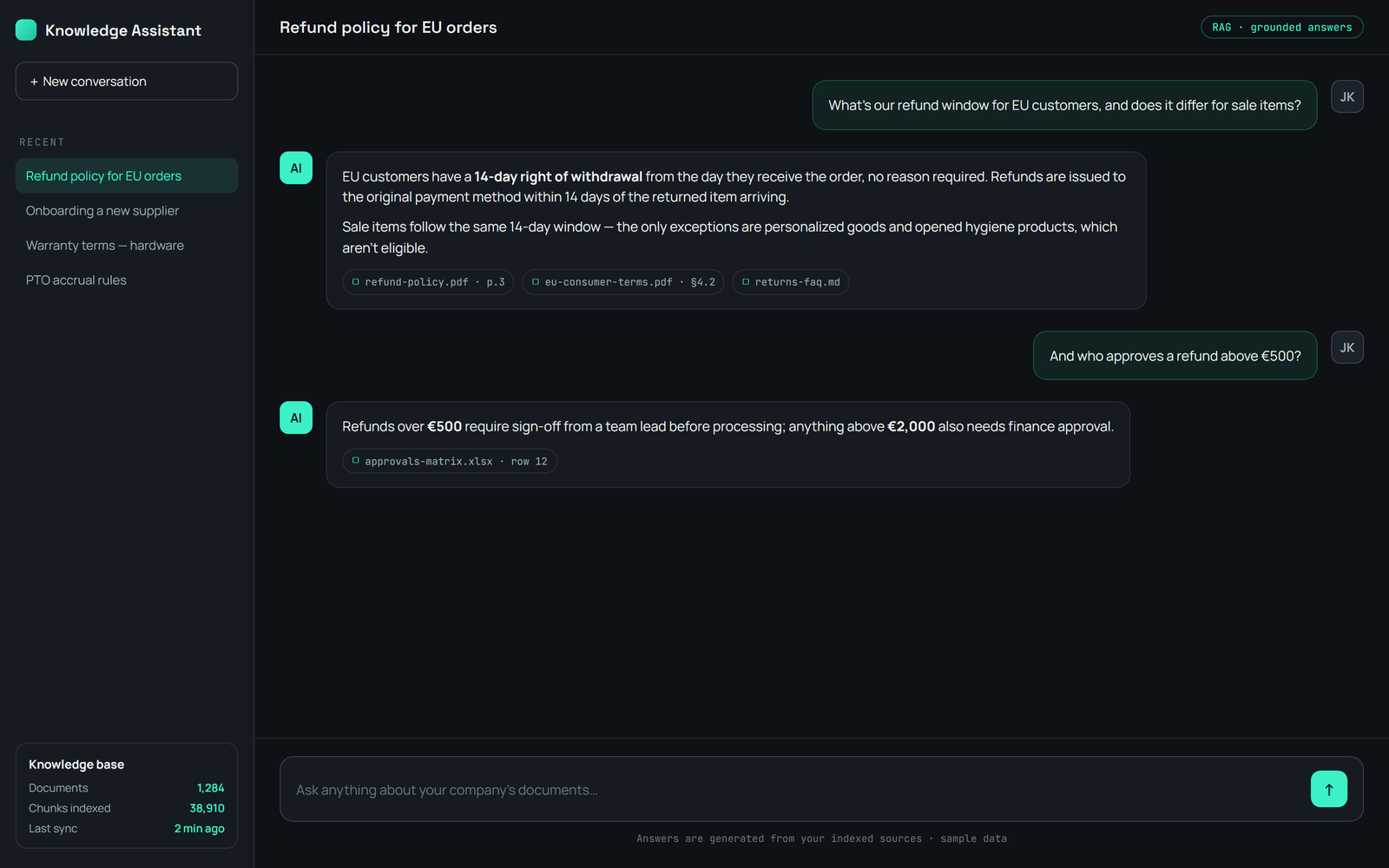
Critical knowledge was scattered across thousands of documents — PDFs, Office files, scans — and impossible to search quickly. Generic chatbots hallucinate and can't be trusted on internal content, with no way to verify where an answer came from.
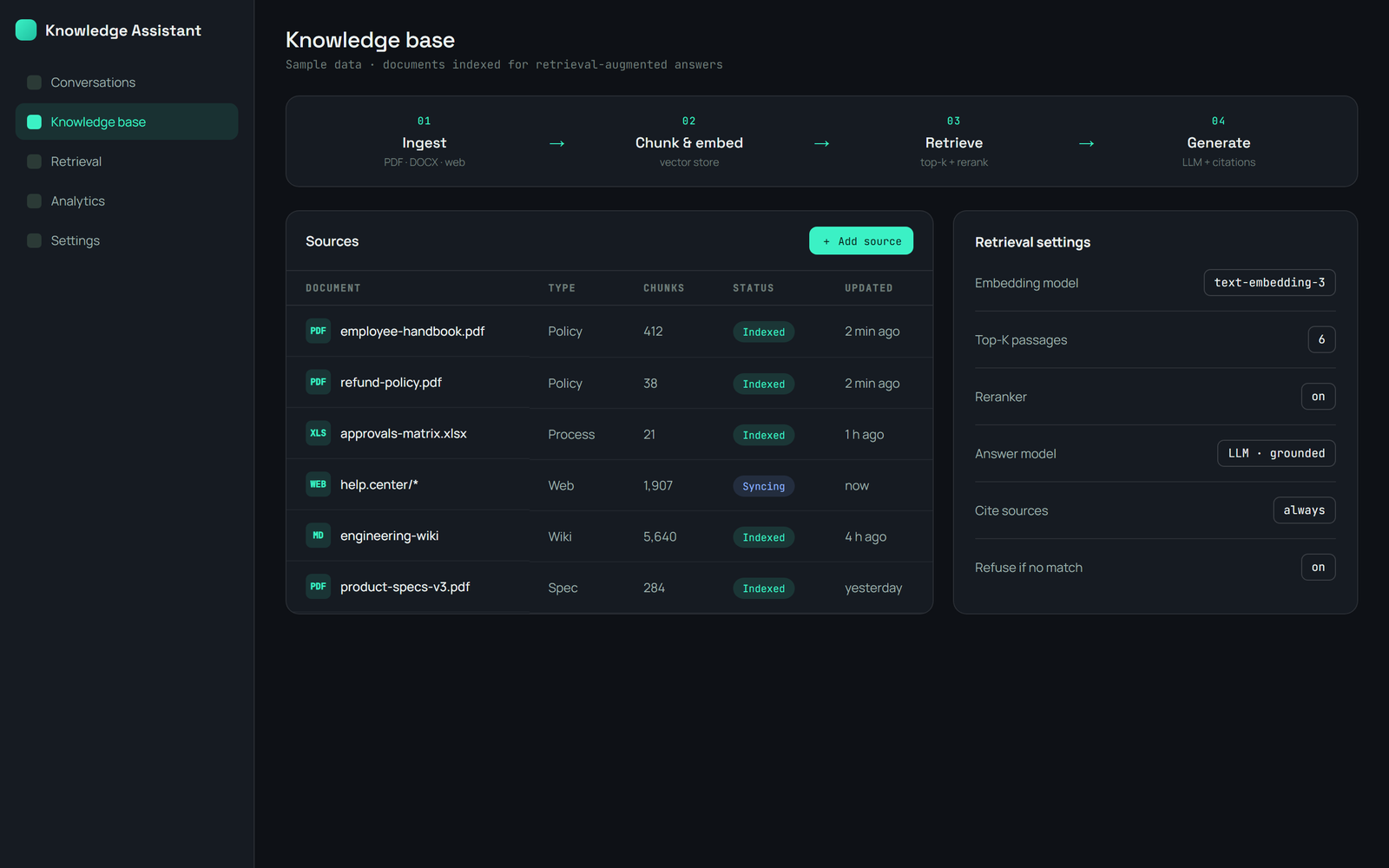
An intelligent document-processing and retrieval platform: it ingests and OCRs documents, classifies them and extracts key fields, then chunks, embeds, and indexes everything into a vector store and a knowledge graph. An agentic RAG assistant answers using hybrid search — semantic plus keyword — with cross-encoder reranking, and composes responses that cite their exact sources, declining when nothing relevant is found. Multi-tenant, with an admin to manage repositories and access.
Grounded, source-cited answers over a company's own documents — every response traceable to the passage it came from, with retrieval tuned for relevance instead of guesswork.
Documents run through a worker pipeline: OCR with a vision model, summarization, document-type classification and field extraction, layout-aware chunking, embedding, and entity-and-relationship extraction into a knowledge graph. At query time an agent draws on vector, keyword, and graph search, reranks the candidates with a cross-encoder, diversifies them, and generates an answer with citations back to the source passages — and refuses rather than guesses when it finds nothing relevant. The models are self-hosted, so the client’s documents stay private, and a companion module extends the same retrieval approach to video.
Inside the platform
Have a project like this in mind?
Get in touch →